글을 시작하며
안녕하세요! PassionFruit200 입니다!
저는 현재 세미나허브의 여러가지 쿼리들을 개발하고 있습니다.
이번 글에서는 애플리케이션단 작성하며 생각했던점들을 글로 남겨보았습니다.
목차
- [쿼리 1] 문제상황
- 쿼리작성
- 탐색방식 리스트업
- Nested Loop Join : Seminar Table Full Scan + company_pk_ix
- Nested Loop Join : seminar_ix1 ( company_no ) + company_pk_ix
- Nested Loop Join : seminar_ix2 ( company_no + inst_dt ) + company_pk_ix
- Nested Loop Join : seminar_ix3 ( inst_dt ) + company_pk_ix
- Nested Loop Join : seminar_ix4 ( inst_dt + company_no ) + company_pk_ix
- Sort Merge Join : No Index
- Hash Join : No Index
- 최종선택
[쿼리 1] 문제상황
세미나 허브 기획팀에서 사용자가 [세미나 목록 버튼]을 누르면, 세미나 허브 목록을 리스트업하여, 사용자에게 보여주려는 기능을 만들려고 합니다.
2500만건의 세미나 테이블과 50만건의 회사 테이블을 활용해 '0초~0.3초' 안에 세미나 제목, 강의 기간, 신청 기간(시작일-종료일), 수강 금액, 신청 가능 인원, 주최 회사명, 신청 상태를 보여주고, 최신 등록순, 가격 내림차순, 가격 오름차순 으로 보여주고, 10개씩 페이지네이션 처리를 통한 목록 조회를 할 수 있도록 처리해달라고 합니다.
1-1. 쿼리 작성
먼저, 쿼리를 작성합니다. 불필요한 데이터 조회(ex. limit 100, 20과 같이)를 줄이기 위해 아래와 같이 2가지로 작성합니다.
- 첫페이지
- 두번째 이후 페이지 쿼리
-- 첫 페이지 조회용 쿼리 select s.NAME as "제목", s.reg_start_date as "신청시작일자", s.reg_end_date as "신청종료일자", s.start_date as "시작일자", s.end_date as "종료일자", s.price as "금액", s.max_capacity as "최대 인원", s.available_seats as "여석", c.company_no as "회사고유번호", c.name as "회사명", case when (s.reg_end_date <= now()) then "신청 가능" when (s.reg_end_date > now()) then "신청 마감" end as '신청가능여부' from SEMINAR s, company c where c.company_no = s.company_no order by s.inst_dt DESC limit 0,10; -- 두번쨰 및 마지막 페이지 조회용 쿼리 select s.NAME as "제목", s.reg_start_date as "신청시작일자", s.reg_end_date as "신청종료일자", s.start_date as "시작일자", s.end_date as "종료일자", s.price as "금액", s.max_capacity as "최대 인원", s.available_seats as "여석", c.company_no as "회사고유번호", c.name as "회사명", case when (s.reg_end_date <= now()) then "신청 가능" when (s.reg_end_date > now()) then "신청 마감" end as '신청가능여부' from SEMINAR s, company c where s.inst_dt <= :page_last_inst_dt and not (s.inst_dt = :page_last_inst_dt and seminar_no >= :page_last_seminar_no) c.company_no = s.company_no order by s.inst_dt DESC limit 0,10;
쿼리 실행시 아래와 같이 나와야 합니다.

해당 쿼리가 실제로 데이터베이스에서 어떻게 검색될 수 있을지 탐색방법 목록을 작성했습니다.
1-2. 탐색방식 리스트업
기본 설정 조건
- Driving Table은 Seminar Table 설정, Driven Table은 Comapny Table 설정합니다.
첫번쨰 이유는, 세미나 목록을 가져오는 것이므로, Seminar와 Company가 한개의 Seminar는 한개의 Company에 의해 공급된다라는 N : 1 공급 관계이므로 N쪽 데이터 입장에서 가져와야합니다. (만약 Company 입장에서 가져오려면 Company 값을 1개로 고정시켜야만 올바르게 가져옵니다.)
두번쨰 이유는, Driving Table은 항상 데이터가 큰 테이블을 기준, Driven Table은 항상 데이터가 작은 테이블을 기준으로 설정해야 탐색 횟수가 줄어듭니다.
모든 탐색방식 리스트업
1. Nested Loop Join : Seminar Table Full Scan + Company Table Full Scan
2. Nested Loop Join : seminar_ix1 ( company_no )
3. Nested Loop Join : seminar_ix2 ( company_no + inst_dt )
4. Nested Loop Join : seminar_ix3 ( inst_dt )
5. Nested Loop Join : seminar_ix4 ( inst_dt + company_no )
6. Nested Loop Join : company_ix1 ( company_no )
7. Nested Loop Join : company_ix2 ( company_no + name )
8. Nested Loop Join : seminar_ix1( company_no ) + company_ix1 ( company_ no )
9. Nested Loop Join : seminar_ix1( company_no ) + company_ix2 ( company_ no + name )
10. Nested Loop Join : seminar_ix2 ( company_no + inst_dt ) + company_ix1 ( company_ no )
11. Nested Loop Join : seminar_ix2 ( company_no + inst_dt ) + company_ix2 ( company_ no + name )
12. Nested Loop Join : seminar_ix3 ( inst_dt ) + company_ix1 ( company_ no )
13. Nested Loop Join : seminar_ix3 ( inst_dt ) + company_ix2 ( company_ no + name)
14. Nested Loop Join : seminar_ix4 ( inst_dt + company_no ) + company_ix1 ( company_ no )
15. Nested Loop Join : seminar_ix4 ( inst_dt + company_no ) + company_ix2 ( company_ no + name)
16. Sort Merge Join : No Index
17. Hash Join : No Index
처음에는 위와 같이 리스트업 시켰습니다.
하지만, 여기서 7가지의 방식으로 목록을 줄일 수 있었습니다.
Driven Table의 조인조건인 company_no는 company table의 고유번호, 즉 Primary Key였습니다. 이 의미는, "반드시" PK Clustered Index가 존재한다는 의미입니다. Mysql에서는 한개의 테이블 당 PK Clustered Index 에 의해 반드시 Primary Key Index가 존재합니다.
그렇다면, PK Clustered Index 를 제가 적용한 이유는 무엇일까요?
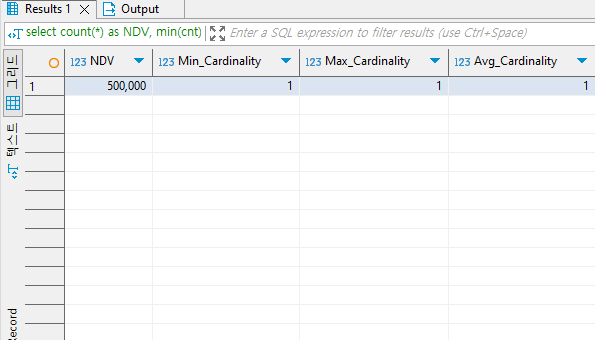
1. 가장 큰 이유는, company_no의 Cardinality는 1로써, 고유번호임을 알 수 있습니다. 고유번호는 당연히 카디널리티가 1입니다. 1건을 찾기 위해 49만 9999건을 찾는 비효율을 피할 수 있습니다.
select count(*) as NDV, min(cnt) as Min_Cardinality, max(cnt) as Max_Cardinality, avg(cnt) as Avg_Cardinality from ( select company_no, count(*) as cnt from company c where (company_no is not null) group by company_no ) c ;
2. PK Clustered Index는 모든 컬럼들이 Leaft Node Value에 저장되어 있습니다. 즉 Covering Index로 사용할 수 있습니다.
(몇몇 분들은 Table Full Scan이 나을 수 있다고 생각할 수 있겠지만, company 테이블의 company_no는 결합조건이기에 그렇지 않습니다.)
기존의 모든 탐색방식에서 Driven Table인 Company Table은 반드시 company_pk_ix 를 사용하도록 수정합니다.
1. Nested Loop Join : Seminar Table Full Scan + company_pk_ix
2. Nested Loop Join : seminar_ix1 ( company_no ) + company_pk_ix
3. Nested Loop Join : seminar_ix2 ( company_no + inst_dt ) + company_pk_ix
4. Nested Loop Join : seminar_ix3 ( inst_dt ) + company_pk_ix
5. Nested Loop Join : seminar_ix4 ( inst_dt + company_no ) + company_pk_ix
6. Sort Merge Join : No Index
7. Hash Join : No Index
다행히, 사전에 불필요한 방법들을 가지치기 할 수 있었습니다.
각 방식의 장단점과 비용을 비교해보겠습니다.
1-2-1. Nested Loop Join : Seminar Table Full Scan + company_pk_ix
시나리오를 작성합니다.
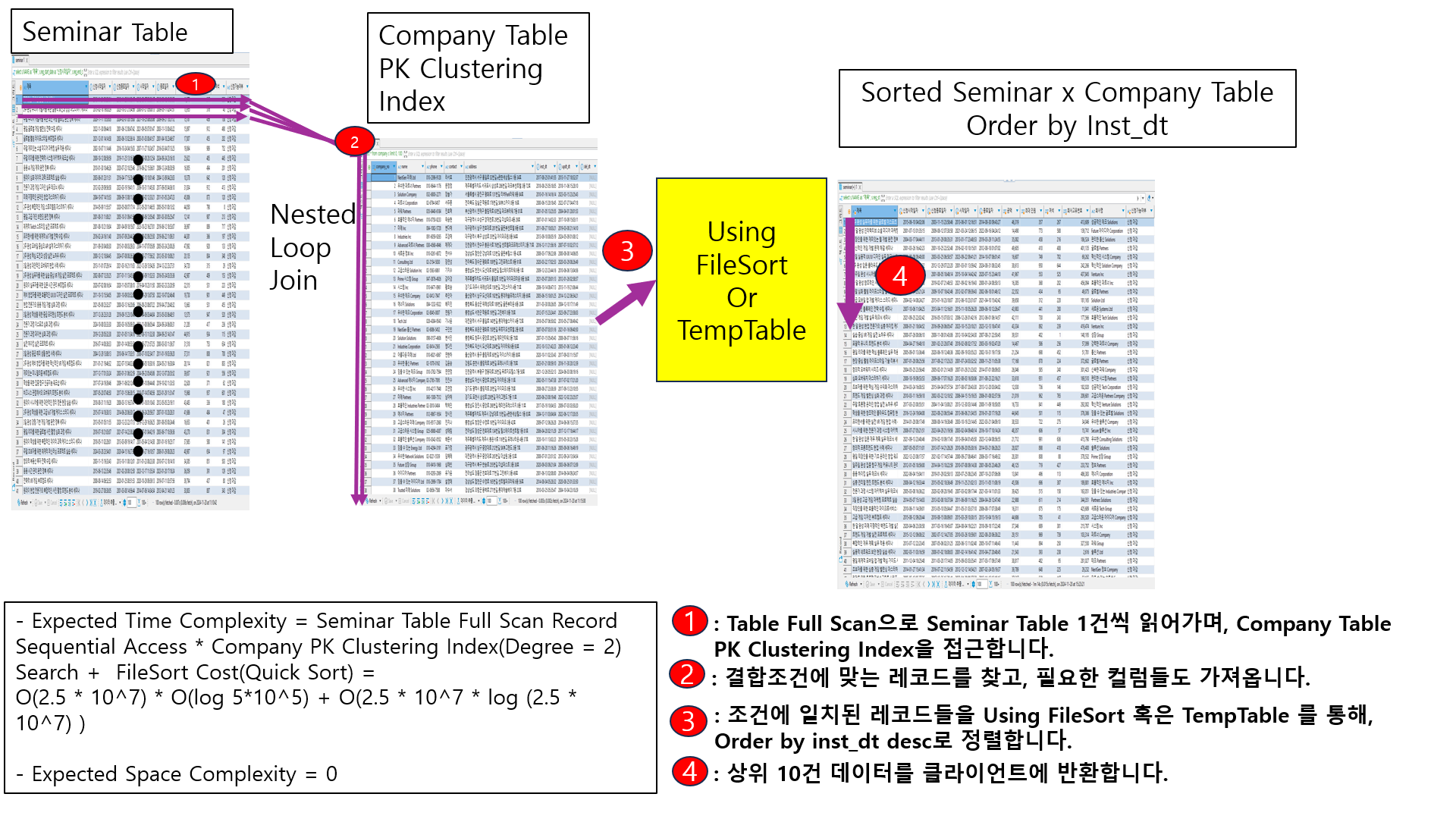
- Table Full Scan으로 Seminar Table 1건씩 읽어가며, Company Table PK Clustering Index을 접근합니다.
- 결합조건에 맞는 레코드를 찾고, 결합하고 필요한 컬럼들도 가져옵니다.
- 조건에 일치된 레코드들을 Using FileSort 혹은 TempTable 을 통해서 저장하고, Order by inst_dt desc로 정렬합니다.
- 상위 10건 데이터를 클라이언트에 반환합니다.
예상 비용 계산식입니다. (B-Tree의 Degree는 2라고 가정. 정렬 함수 또한 QuickSort라고 가정. 통제불가능 변수 무시 )
Expected Time Complexity = Seminar Table Full Scan Record Sequential Access * Company PK Clustering Index( Base = Degree = 2 ) Search + FileSort Cost(Quick Sort)
= O(2.5 * 10^7) * O(log 5*10^5) + O(2.5 * 10^7 * log (2.5 * 10^7) )
Expected Space Complexity = 0
첫번쨰 페이지 호출 쿼리입니다. 제가 원하는 바로 동작시키기 위해 index hint를 사용한점을 살펴보세요. (Mysql에서는 Full Scan Table Hint가 존재하지 않습니다. )
select s.NAME as "제목", s.reg_start_date as "신청시작일자", s.reg_end_date as "신청종료일자", s.start_date as "시작일자", s.end_date as "종료일자", s.price as "금액", s.max_capacity as "최대 인원", s.available_seats as "여석", c.company_no as "회사고유번호", c.name as "회사명", case when (s.reg_end_date > now()) then "신청 가능" when (s.reg_end_date <= now()) then "신청 마감" end as '신청가능여부' from SEMINAR s ignore index(primary, seminar_ix1, seminar_ix3, seminar_ix4), company c use index(primary) where c.company_no = s.company_no order by s.inst_dt DESC limit 0,10;
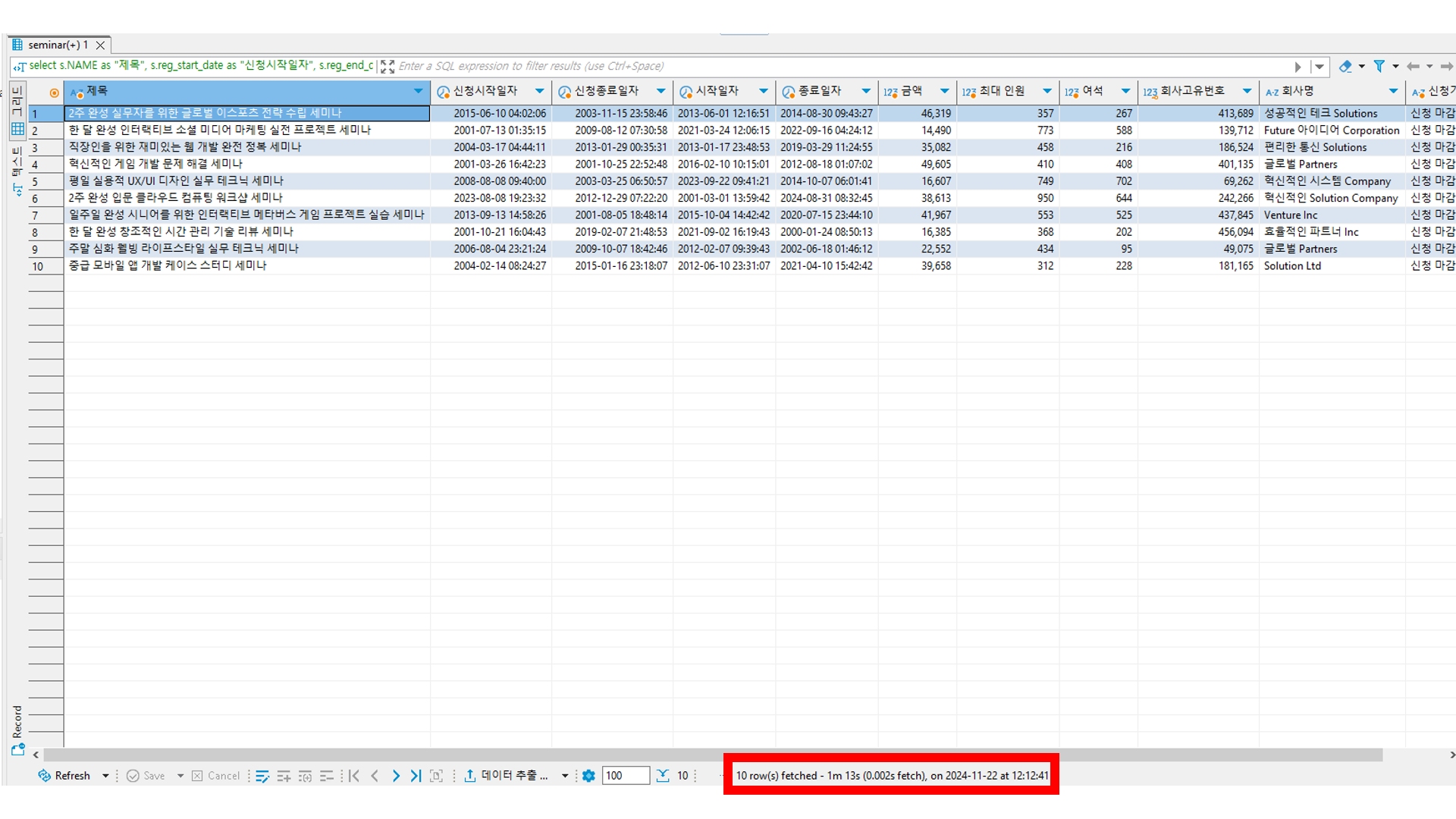
1m 13s 가 걸립니다. 제 목표인 0~1초 보다 7300% 초과입니다.
실행계획입니다.
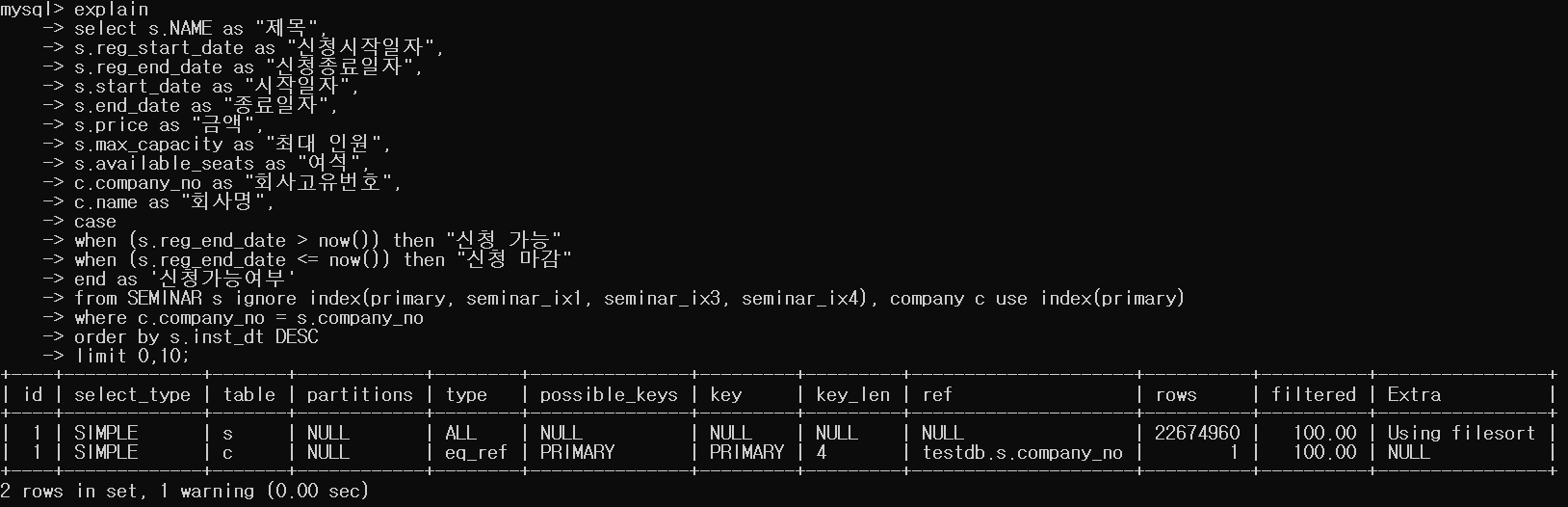

예상한대로, 실행계획이 나왔습니다.
혹시 모르니 Tree 형태로도 확인합니다.
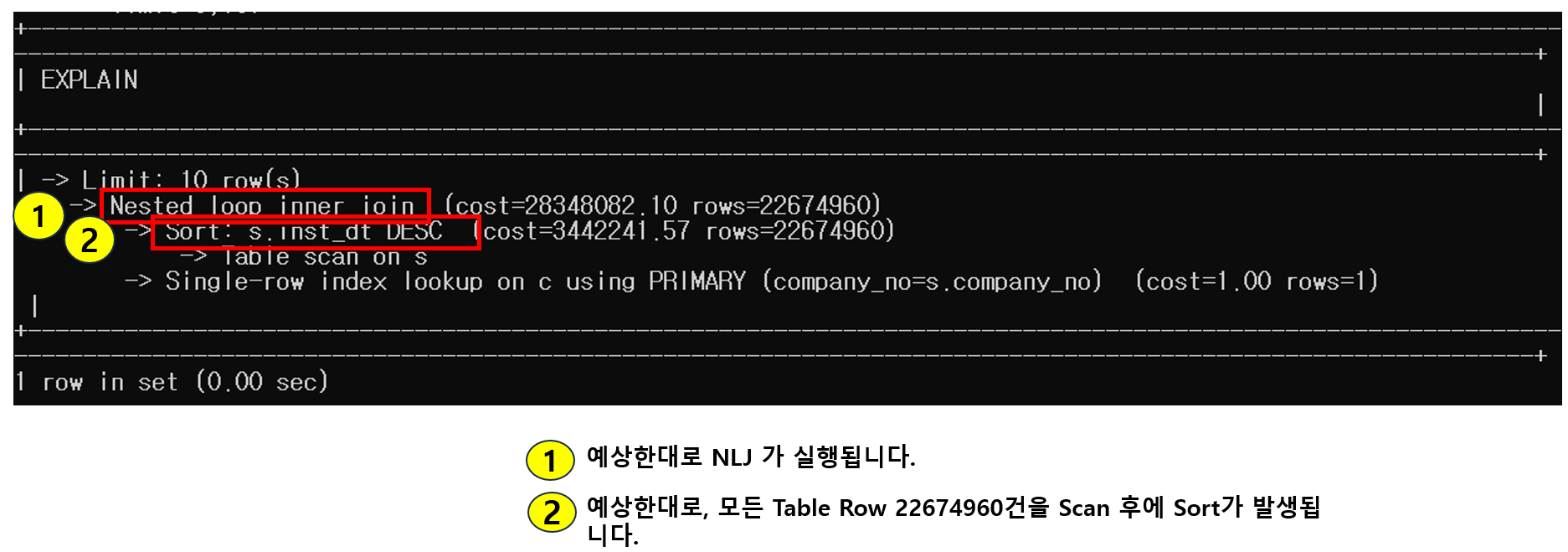
시나리오와 일치합니다.
1-2-2. Nested Loop Join : seminar_ix1 ( company_no ) + company_pk_ix
시나리오입니다.

- seminar_ix1(company_no) 으로 company가 정렬된 순서대로 읽으며, PK Clustered Index를 통해 인덱스 value값(Column)을 가져옵니다.
- 결합조건에 맞는 레코드를 찾고, 필요한 컬럼들도 가져옵니다.
- Using FileSort 혹은 TempTable 을 통해서 저장하고, Order by inst_dt desc로 정렬합니다.
- Sorted Semiar x Company Table 상위에서 10건을 선택합니다
시나리오에서 보이듯이, 이 방식은 전혀 도움이 안됩니다.
이유는, Driving Table인 Seminar Table의 조인컬럼에 Index를 설정하였기 때문입니다. 이 조인컬럼은 조인 조건외에 조건으로도 사용되지 않았고, 정렬 조건으로도 사용되지 않았습니다. 더더욱이 Driving Table이었기에 의미가 없습니다.
1-2-2 방식은 Seminar_ix1 을 만들어서, Space complexity 가 (레코드 수) x (컬럼 크기) = (2.5 * 10^7) * (2^32 bit)를 사용함에도 불구하고, 아래의 TimeComplexity가 1-2-1의 Time Complexity와 Space Complexity 측면 모두에서 효율이 떨어집니다.
예상 비용 계산식입니다. (B-Tree의 Degree는 2라고 가정. 정렬 함수 또한 QuickSort라고 가정. 통제불가능 변수 무시 )
Expected Time Complexity = Seminar_ix1 * Seminar PK Clustering Index Search * Company PK Clustering Index(Degree = 2) Search + FileSort Cost(Quick Sort)
= O(2.5 * 10^7) * O(log 2.5 * 10^7) * O(log 5*10^5) + O(2.5 * 10^7 * log (2.5 * 10^7) )
Expected Space Complexity = Seminar_ix 1
= O( (4 byte(company_no) + 4 byte (PK)) * 2.5 *10^7)
첫번쨰 페이지 호출 쿼리입니다. 제가 원하는 바로 동작시키기 위해 index hint를 사용한점을 살펴보세요.
select s.NAME as "제목", s.reg_start_date as "신청시작일자", s.reg_end_date as "신청종료일자", s.start_date as "시작일자", s.end_date as "종료일자", s.price as "금액", s.max_capacity as "최대 인원", s.available_seats as "여석", c.company_no as "회사고유번호", c.name as "회사명", case when (s.reg_end_date > now()) then "신청 가능" when (s.reg_end_date <= now()) then "신청 마감" end as '신청가능여부' from SEMINAR s use index(seminar_ix1), company c use index(primary) where c.company_no = s.company_no order by s.inst_dt DESC limit 0,10;
1m 5s가 걸렸습니다.
실행계획입니다.


예상한대로 이 방식은 전혀 도움 안됩니다.
1-2-3. Nested Loop Join : seminar_ix2 ( company_no + inst_dt ) + company_pk_ix
인덱스의 정렬 특성상, 1-2-2 와 유사하게 company_no가 선두컬럼에 존재하므로 전혀 소용없습니다.
inst_dt는 company_no에 의해 정렬되어있다는 점을 이해하면 알 수 있습니다.
1-2-4. Nested Loop Join : seminar_ix3 ( inst_dt ) + company_pk_ix
시나리오입니다.
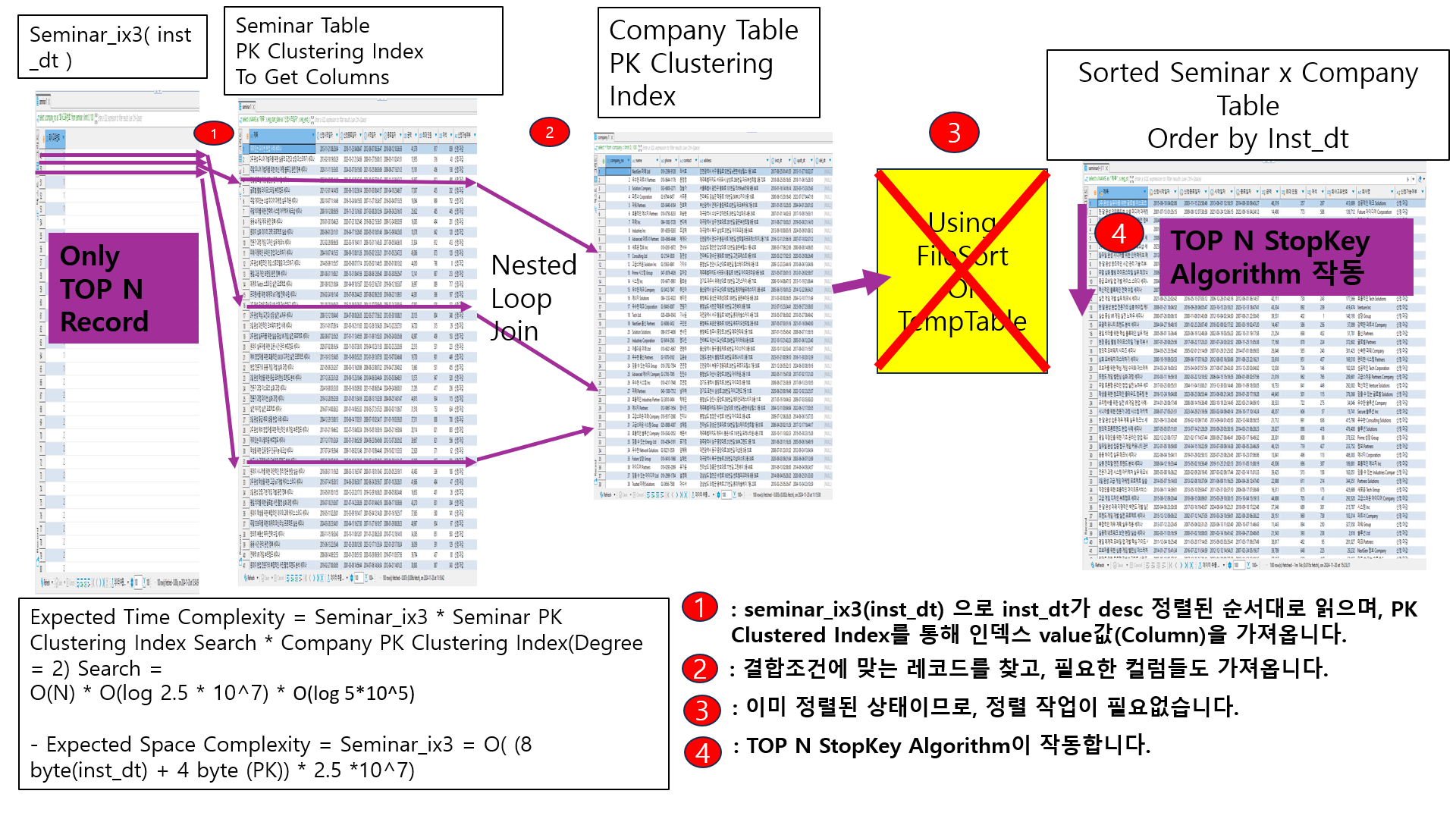
- seminar_ix3(inst_dt) 으로 inst_dt가 desc 정렬된 순서대로 읽으며, PK Clustered Index를 통해 인덱스 value값(Column)을 가져옵니다.
- 결합조건에 맞는 레코드를 찾고, 필요한 컬럼들도 가져옵니다.
- 이미 정렬된 상태이므로, 정렬 작업이 필요없습니다.
- TOP N StopKey Algorithm이 작동합니다.
예상 비용 계산식입니다. (B-Tree의 Degree는 2라고 가정. 정렬 함수 또한 QuickSort라고 가정. 통제불가능 변수 무시)
Expected Time Complexity = Seminar_ix3 * Seminar PK Clustering Index Search * Company PK Clustering Index(Degree = 2) Search
= O(N) * O(log 2.5 * 10^7) * O(log 5*10^5)
Expected Space Complexity = Seminar_ix3
= O( (8 byte(inst_dt) + 4 byte (PK)) * 2.5 *10^7)
select s.NAME as "제목", s.reg_start_date as "신청시작일자", s.reg_end_date as "신청종료일자", s.start_date as "시작일자", s.end_date as "종료일자", s.price as "금액", s.max_capacity as "최대 인원", s.available_seats as "여석", c.company_no as "회사고유번호", c.name as "회사명", case when (s.reg_end_date > now()) then "신청 가능" when (s.reg_end_date <= now()) then "신청 마감" end as '신청가능여부' from SEMINAR s use index(seminar_ix3), company c use index(primary) where c.company_no = s.company_no order by s.inst_dt DESC limit 0,10;
0.008초가 걸립니다.
실행계획입니다.


시나리오와 일치합니다.
1-2-5. Nested Loop Join : seminar_ix4 ( inst_dt + company_no ) + company_pk_ix
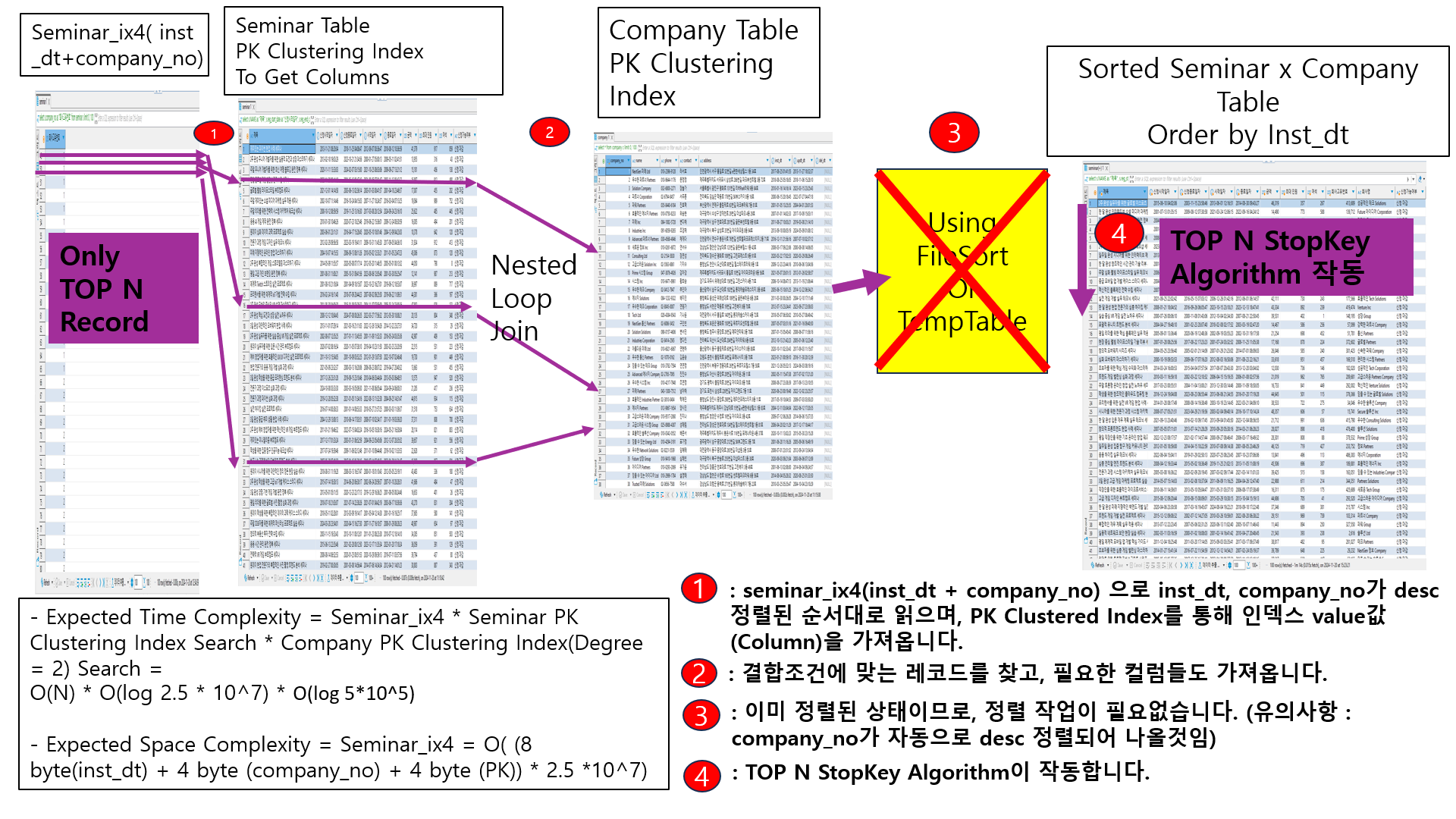
- seminar_ix4(inst_dt + company_no) 으로 inst_dt, company_no가 desc 정렬된 순서대로 읽으며, PK Clustered Index를 통해 인덱스 value값(Column)을 가져옵니다.
- 결합조건에 맞는 레코드를 찾고, 필요한 컬럼들도 가져옵니다.
- 이미 정렬된 상태이므로, 정렬 작업이 필요없습니다. (유의사항 : company_no가 자동으로 desc 정렬되어 나올것임)
- TOP N StopKey Algorithm이 작동합니다.
예상 비용 계산식입니다. (B-Tree의 Degree는 2라고 가정. 정렬 함수 또한 QuickSort라고 가정. 통제불가능 변수 무시)
Expected Time Complexity = Seminar_ix4 * Seminar PK Clustering Index Search * Company PK Clustering Index(Degree = 2) Search
= O(N) * O(log 2.5 * 10^7) * O(log 5*10^5)
Expected Space Complexity = Seminar_ix4
= O( (8 byte(inst_dt) + 4 byte (company_no) + 4 byte (PK)) * 2.5 *10^7)
select s.NAME as "제목", s.reg_start_date as "신청시작일자", s.reg_end_date as "신청종료일자", s.start_date as "시작일자", s.end_date as "종료일자", s.price as "금액", s.max_capacity as "최대 인원", s.available_seats as "여석", c.company_no as "회사고유번호", c.name as "회사명", case when (s.reg_end_date > now()) then "신청 가능" when (s.reg_end_date <= now()) then "신청 마감" end as '신청가능여부' from SEMINAR s use index(seminar_ix4), company c use index(primary) where c.company_no = s.company_no order by s.inst_dt DESC limit 0,10;
실행시간은 0.003sec가 소요되었습니다.
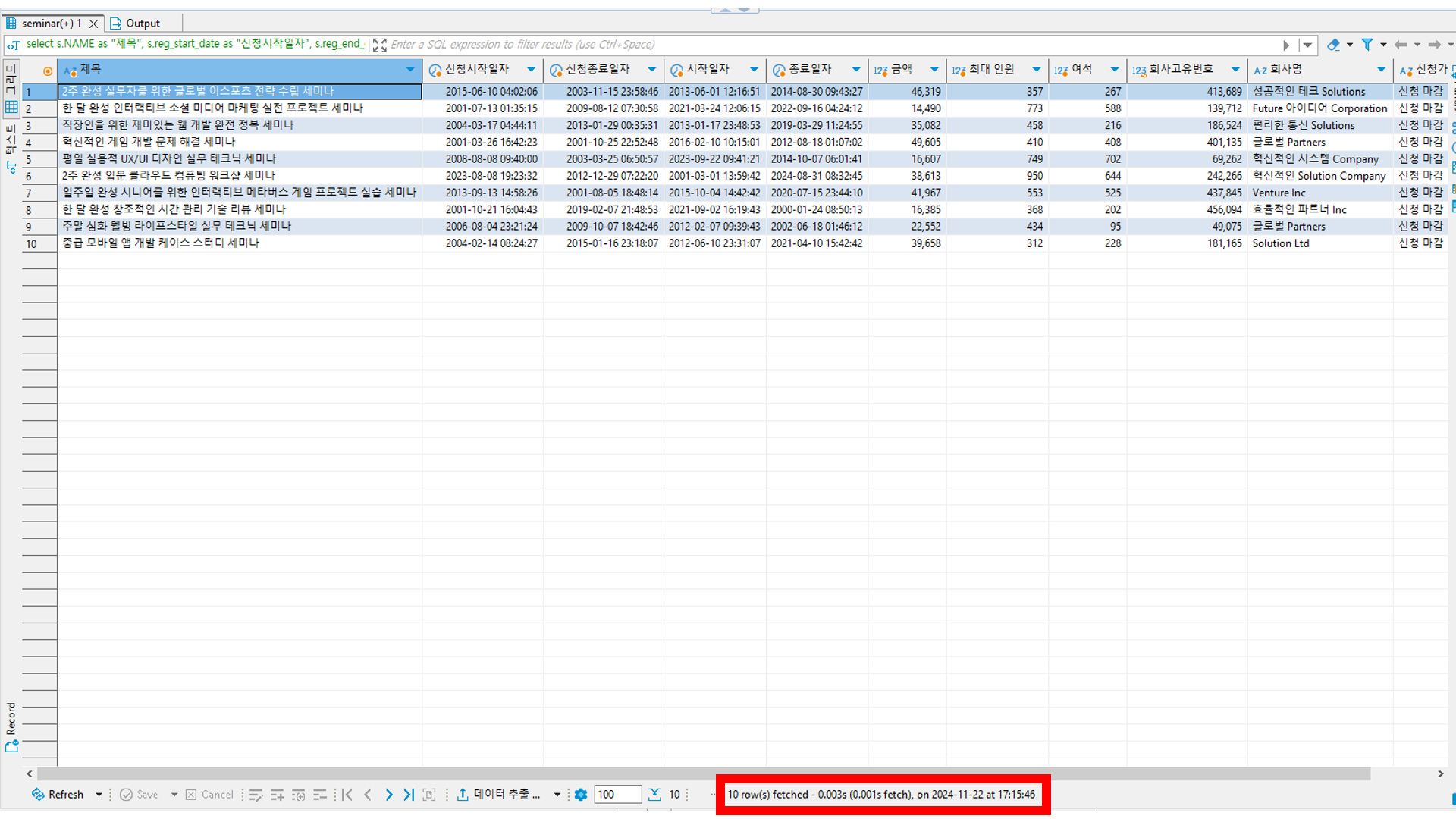

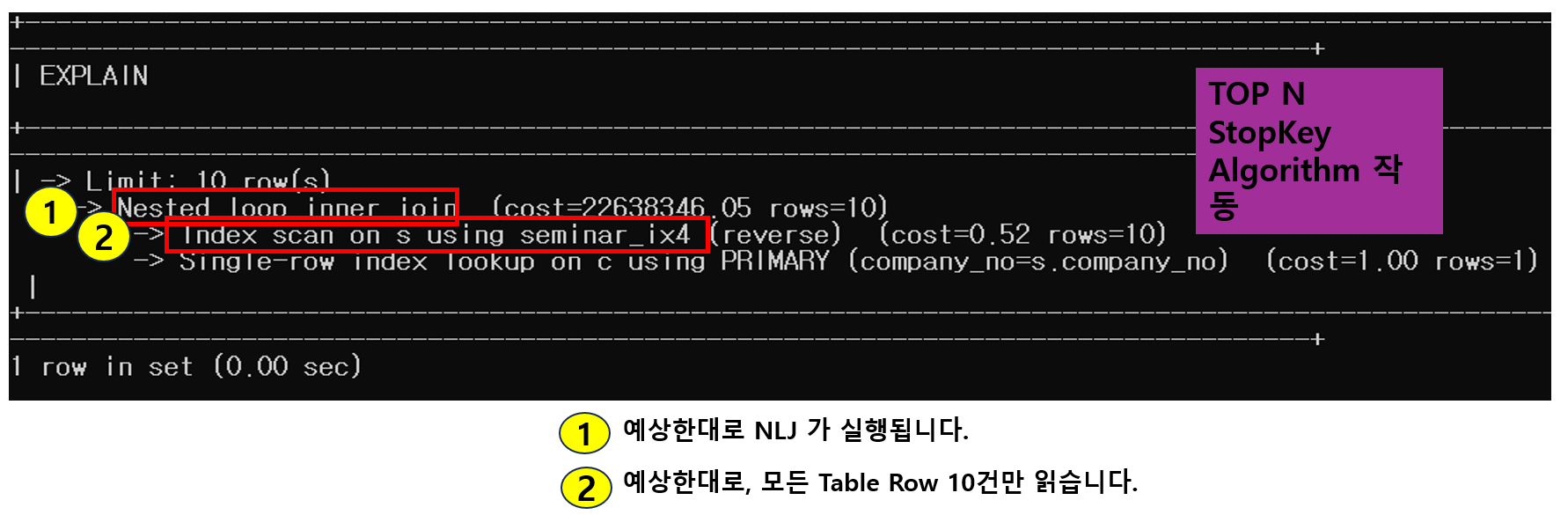
시나리오와 일치합니다.
즉, 즉, company_no의 고유번호가 클수록 우선순위가 높습니다.
1-2-6. Sort Merge Join : No Index
Sort Merge Join은 매번 모든 쿼리를 Sort하는 과정이 수반됩니다. 앞에서 살펴보았듯이, 2500만개 x 50만개 데이터를 Sort하고 반환한다면, 절대 빠를 수 없습니다. 즉, 부분범위처리가 불가합니다.
1-2-7. Hash Join : No Index
이 방식은 수행빈도가 매우 높은 쿼리(OLTP) 환경에서는 좋지 않습니다. Hash 함수가 일회성으로 사용되고 종료되기 떄문입니다.
이 방식이 사용되기 위해서는, NLJ 보다 압도적 효율을 가지고 있어야하는데 이미 1-2-5 시나리오에서 보이듯 해당 방식보다 압도적 속도를 가지는건 어렵습니다. 즉, 부분범위처리가 불가합니다.
1-3.최종선택
최종선택할 방식은 1-2-4. Nested Loop Join : seminar_ix3 ( inst_dt ) + company_pk_ix 방식입니다.
선택한 측면은 Time Complexity와 Space Complexity 2가지 측면을 기준으로 선택했습니다.
- Time Complexity = O(N) * O(log 2.5 * 10^7) * O(log 5*10^5) 로써, 레코드 개수는 통제불가능한 변수이기에 우리가 통제 가능한 N값으로만 시간복잡도가 결정됩니다.
만약 O(2.5 * 10^7) * O(log 2.5 * 10^7) * O(log 5*10^5) 과 O(N) * O(log 2.5 * 10^7) * O(log 5*10^5) 의 효율을 비교해보면,O( 2.5 * 10^7 ) / O ( N = 한 페이지당 개수 )만큼 우리가 선정한 방식이 빠릅니다. 심지어 이 방식은 Using FIleSort가 실행된 1-2-1, 1-2-2 의 FileSort 방식과 비교한 값이 아닙니다.
- Space Complexity = O( (8 byte(inst_dt) + 4 byte (PK)) * 2.5 *10^7) 로써, 적정한 수준입니다.
현재로써는, 하나의 쿼리만 분석했지만 더 많은 검색 쿼리를 추가하며 한개의 테이블에 5개 정도의 인덱스를 구성하며 가장 적합한 인덱스 구성을 찾아나갈 예정입니다.