저희 프로젝트에서는 세미나의 각 조건별로 세미나를 검색할 수 있는 기능을 제공하는데요. 적재된 세미나 데이터가 많아진다면 발생할 수 있는 성능이슈를 ElasticSearch 를 활용함으로써 해결해보는 과정을 담아보려고 합니다.

ElasticSearch에 대한 관심이 생긴 계기는, 데이터베이스의 인덱스를 커버링 인덱스로 적용해보며입니다. 데이터베이스의 인덱스 구조를 공부해면서, '%키워드%' 일경우에는 Full Scan 으로 검색한다는것을 알게되었는데요. 또한, 관계형 데이터베이스에서는 처음 데이터 Row부터 끝 데이터 Row까지 모두 Full Scan 해야한다는 특성 때문에 이러한 검색량이 많아질수록 늦어질 수 밖에 없습니다.
세미나의 인덱스를 모델링하는 과정과 ElasticSearch를 Spring Data ElasticSearch를 검색하는 과정을 담아보았습니다.
1. 먼저 Seminar의 Index를 생성합니다.
1-1. SeminarDocument.class
ElasticSearch에 적재할 데이터 Mapping으로 선언합니다.
실질적인 매핑은 es-seminar-mapping.json에서 mapping을 직접적으로 선언합니다.
@Getter @Setter @Document(indexName = Indices.SEMINAR_INDEX) @Setting(settingPath = "elasticsearch/mappings/es-seminar-settings.json") @Mapping(mappingPath = "elasticsearch/mappings/es-seminar-mapping.json") @ToString @Builder public class SeminarDocument { @Id @Field(type = FieldType.Keyword) private Long seminar_no; @Field(type = FieldType.Text) private String seminar_name; @Field(type = FieldType.Text) private String seminar_explanation; @Field(type = FieldType.Keyword) private Long seminar_price; @Field(type = FieldType.Keyword) private Long seminar_max_participants; @Field(type = FieldType.Date, format = DateFormat.date_hour_minute_second_millis) private LocalDateTime inst_dt; @Field(type = FieldType.Date, format = DateFormat.date_hour_minute_second_millis) private LocalDateTime updt_dt; }
1-2. 사용할 Index의 구조입니다.
아래의 REST API 호출을 통해 Index를 생성합니다.
PUT seminar { "settings": { "index": { "routing": { "allocation": { "include": { "_tier_preference": "data_content" } } }, "number_of_shards": "1", "number_of_replicas": "1", "analysis": { "analyzer": { "seminar_explanation_analyzer": { "type": "custom", "char_filter": ["html_strip"], "tokenizer": "nori_tokenizer_discard", "filter": ["lowercase", "english_stop_filter", "snowball", "nori_part_of_speech"] }, "seminar_name_analyzer": { "type": "custom", "char_filter": ["html_strip"], "tokenizer": "nori_tokenizer_discard", "filter": ["lowercase", "english_stop_filter", "snowball"] } }, "filter": { "english_stop_filter": { "type": "stop", "stopwords": [ "a", "an", "the", "is", "at", "on", "in", "of", "and", "or" ] }, "nori_part_of_speech": { "type": "nori_part_of_speech", "stoptags": [ "E", "IC", "J", "MAG", "MAJ", "MM", "SP", "SSC", "SSO", "SC", "SE", "XPN", "XSA", "XSN", "XSV", "UNA", "NA", "VSV" ] } }, "tokenizer": { "nori_tokenizer_discard": { "type": "nori_tokenizer", "decompound_mode": "discard" } } } } }, "mappings": { "properties": { "_class": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "inst_dt": { "type": "date" }, "seminar_explanation": { "type": "text", "analyzer": "seminar_explanation_analyzer" }, "seminar_max_participants": { "type": "long" }, "seminar_name": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } }, "analyzer": "seminar_name_analyzer" }, "seminar_no": { "type": "long" }, "seminar_price": { "type": "long" }, "updt_dt": { "type": "date" } } } }
Index의 텍스트 분석 과정은 Char Filter, tokenizer, filter 이렇게 3가지의 순서를 거쳐서 진행됩니다.
Index를 analyzer, tokenizer, filter 를 순서대로 설명해보겠습니다. Char Filter는 이미 구현된 구현체를 사용했습니다.
1-2-1. 선언한 Analyzer 입니다.
"analyzer": { "seminar_explanation_analyzer": { "type": "custom", "char_filter": ["html_strip"], "tokenizer": "nori_tokenizer_discard", "filter": ["lowercase", "english_stop_filter", "snowball", "nori_part_of_speech"] }, "seminar_name_analyzer": { "type": "custom", "char_filter": ["html_strip"], "tokenizer": "nori_tokenizer_discard", "filter": ["lowercase", "english_stop_filter", "snowball"] } },
- seminar_name_analyzer : 세미나의 이름 전용의 analyzer입니다.
- type: "custom" 사용자 설정으로써 Custom입니다..
- char_filter: ["html_strip"] HTML 태그를 없애주기 위한 Character Filter 입니다.
- tokenizer : "nori_tokenizer_discard" 로 한글 형태소 분석기의 Nori의 tokenizer를 사용합니다. (아래에 추가로 설명합니다.)
- "filter": ["lowercase", "english_stop_filter", "snowball", "nori_part_of_speech"]
- "lowercase" : 대문자를 소문자로 변환합니다.
- "english_stop_filter" : 영어 불용어를 stop word로 지정하여 인덱스에 넣지 않습니다.
- "snowball" : 언어처리를 위한 스태밍(Stemming) 알고리즘 중 하나입니다. 단어에서 접미사나 어미를 제거하여 어간을 추출하는 과정을 의미합니다.
- 예로 들어보면, "running", "runs", "ran"과 같은 단어들이 모두 "run" 이라는 어간을 가지고 있습니다. 이러한 단어들을 하나의 "run"이라는 어간으로 검색하면 모두 검색됩니다.
- seminar_explanation_analyzer : 세미나의 설명 전용의 analyzer 입니다.
- type: "custom" 사용자 설정으로써 Custom입니다..
- char_filter: ["html_strip"] HTML 태그를 없애주기 위한 Character Filter 입니다.
- tokenizer : "nori_tokenizer_discard" 로 한글 형태소 분석기의 Nori의 tokenizer를 사용합니다. (아래에 추가로 설명합니다.)
- "filter": ["lowercase", "english_stop_filter", "snowball", "nori_part_of_speech"]
- "lowercase" : 대문자를 소문자로 변환합니다.
- "english_stop_filter" : 영어 불용어를 stop word로 지정하여 인덱스에 넣지 않습니다.
- "snowball" : 언어처리를 위한 스태밍(Stemming) 알고리즘 중 하나입니다. 단어에서 접미사나 어미를 제거하여 어간을 추출하는 과정을 의미합니다.
- 예로 들어보면, "running", "runs", "ran"과 같은 단어들이 모두 "run" 이라는 어간을 가지고 있습니다. 이러한 단어들을 하나의 "run"이라는 어간으로 검색하면 모두 검색됩니다.
1-2-2 이제 "tokenizer"에 대해 알아보겠습니다.
먼저 제가 사용한 토크나이저에 대해 알아보기전에 먼저, 한국어 텍스트를 처리하기 위해 Nori Tokenizer에 대해 간략히 설명해보겠습니다.
"nori toeknizer"에는 "decompound_mode"의 옵션을 통해 한국어 복합어의 저장방식을 결정할 수 있습니다.
3가지의 설정이 있는데요.
Elastic 공식문서의 설명을 통해 이해해보았습니다.
https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis-nori-tokenizer.html
- "decompound_mode" : "none"
- 어근을 분리하지 않고 완성된 합성어만 저장합니다.
- 예시로 들어보면, "가거도항 가곡역" 라고 입력되었다고 하면, ["가거도항", "가곡역"] 과 같이 그대로 토큰화됩니다.
- 추가 예시를 들어보면, "달린다" 라고 입력되었다고하면, ["달린다"] 와 같이 그대로 토큰화됩니다.
- "decompound_mode" : "discard"
- 합성어를 분리하여 각 어근만 저장합니다.
- 예시로 들어보면, "가거도항 가곡역" 라고 입력되었다고 하면, ["가거도", "항", "가곡", "역"] 과 같이 토큰화됩니다. 조금 헷갈릴 수 있는데요
- 추가 예를들어보면, 합성어를 분리하여 각 어근만 저장한다는 말은 예로 들면 "달린다" 가 있을때 ["달리", "다"] 이렇게 구분된다는 의미입니다.
- discard 옵션이 기본 Default 옵션입니다. 만약에 nori_tokenizer를 바로 따로 tokenizer를 선언하지 않고 사용한다면 discard옵션이 사용됩니다.
- "decompound_mode" : "mixed"
- 어근과 합성어를 모두 저장합니다.
- 예시로 들어보면, "가거도항 가곡역"라고 입력되었다면, ["가거도항", "가거도", "항", "가곡역", "가곡", "역"] 과 같이 토큰화됩니다.
- 추가 예를들어보면, "달린다" 가 있을때 ["달린다", "달리", "다"] 과 같이 토큰화됩니다.
- 이 옵션을 사용할경우 많은 인덱스가 생성되어 다양한 검색에는 좋을 것이고, 용량에는 부족함이 있을 수 있습니다.
nori 플러그인을 사용하기 위해 아래의 명령어를 통해 analysis-nori Plugin을 먼저 다운합니다.
$ bin/elasticsearch-plugin install analysis-nori
사용할 tokenizer입니다.
"tokenizer": { "nori_tokenizer_discard": { "type": "nori_tokenizer", "decompound_mode": "discard" } },
- "nori_tokenizer_discard":
- "type": "nori_tokenizer"
- 기본적으로 nori_tokenizer를 사용할것이라고 선언합니다.
- "decompound_mode" : "discard"
- 합성어를 분리하여 각 어근만 저장하는 옵션을 사용합니다.
- "type": "nori_tokenizer"
1-2-3. Filter
"filter": { "english_stop_filter": { "type": "stop", "stopwords": ["a", "an", "the", "is", "at", "on", "in", "of", "and", "or"] }, "nori_part_of_speech": { "type": "nori_part_of_speech", "stoptags": [ "E", "IC", "J", "MAG", "MAJ", "MM", "SP", "SSC", "SSO", "SC", "SE", "XPN", "XSA", "XSN", "XSV", "UNA", "NA", "VSV" ] } }
- "english_stop_filter" : 영어 불용어를 처리하기 위한 필터입니다.
- type : stop
- 불용어를 처리하는 filter라는것을 명시합니다.
- "stopwords": ["a", "an", "the", "is", "at", "on", "in", "of", "and", "or"]
- 불용어로 처리할 단어를 직접 설정합니다.
- type : stop
- "nori_part_of_speech" : Elasticsearch의 Nori 플러그인에서 제공하는 필터입니다. 한글 형태소를 분석하며 특정 품사 (Part of Speech)를 필터링하여 색인하는데 사용됩니다.
- 예를 들어보겠습니다. 위의 예시 중하나인 "가거도항 가곡역" 을 분석해봅니다.
- "가거도"는 "NNP(Proper Noun)으로써 고유 명사를 의미합니다.
- "항"는 "NNP(Proper Noun)으로써 고유 명사를 의미합니다.
- "가곡"는 "NNP(Proper Noun)으로써 고유 명사를 의미합니다.
- "역"는 "NNP(Proper Noun)으로써 고유 명사를 의미합니다.
- 이번 예시는 모두 고유명사를 의미합니다. 만약에 전치사이거나 동사, 대명사일경우로 나뉘기도 하겠습니다.
- 만약에 동사일경우는 "VV", 대명사일경우는 " NP" 등등이 있게습니다.
- 제가 설정한 stoptags 는 default 불용어입니다.
- 예를 들어보겠습니다. 위의 예시 중하나인 "가거도항 가곡역" 을 분석해봅니다.
만약 단어의 형태를 알고싶다면 아래와 같이 "explain" 옵션을 활용하여 확인할 수 있습니다.
"가거도항 가곡역"을 한글형태소로 분석요청합니다. GET seminar/_analyze { "tokenizer": "nori_discard", "text": [ "가거도항 가곡역" ], "explain": true } 형태소 분석결과 { "detail": { "custom_analyzer": true, "charfilters": [], "tokenizer": { "name": "nori_discard", "tokens": [ { "token": "가거도", "start_offset": 0, "end_offset": 3, "type": "word", "position": 0, "bytes": "[ea b0 80 ea b1 b0 eb 8f 84]", "leftPOS": "NNP(Proper Noun)", "morphemes": null, "posType": "MORPHEME", "positionLength": 1, "reading": null, "rightPOS": "NNP(Proper Noun)", "termFrequency": 1 }, { "token": "항", "start_offset": 3, "end_offset": 4, "type": "word", "position": 1, "bytes": "[ed 95 ad]", "leftPOS": "NNG(General Noun)", "morphemes": null, "posType": "MORPHEME", "positionLength": 1, "reading": null, "rightPOS": "NNG(General Noun)", "termFrequency": 1 }, { "token": "가곡", "start_offset": 5, "end_offset": 7, "type": "word", "position": 2, "bytes": "[ea b0 80 ea b3 a1]", "leftPOS": "NNP(Proper Noun)", "morphemes": null, "posType": "MORPHEME", "positionLength": 1, "reading": null, "rightPOS": "NNP(Proper Noun)", "termFrequency": 1 }, { "token": "역", "start_offset": 7, "end_offset": 8, "type": "word", "position": 3, "bytes": "[ec 97 ad]", "leftPOS": "NNG(General Noun)", "morphemes": null, "posType": "MORPHEME", "positionLength": 1, "reading": null, "rightPOS": "NNG(General Noun)", "termFrequency": 1 } ] }, "tokenfilters": [] } }
이로써 제가 Seminar Index에 사용할 옵션들을 모두 정리했습니다.
1-3 Seminar Index를 Spring에서 관리해보기
이제는, Spring에서 Spring Data ElasticSearch 5.x 를 활용하여 마치 ORM 처럼, Index를 자동으로 생성해주는 설정을 진행해보겠습니다.
그렇기 위해서는 es-seminar-settings.json과 es-member-settings.json이 사용됩니다. 물론 위의 SeminarDocument에서 설정을 하기도하였지만, 좀 더 세밀한 설정을 위해서 아래의 json 파일을 사용합니다.
json 파일을 만들다보면, setting.json 같은경우 "setting"으로 묶여있지 않고, mapping.json은 "mapping"으로 묶여있지 않습니다. Spring에서 설정하기 위해서는 아래와 같이 사용해야합니다.
1-3-1 es-seminar-settings.json
아래의 설정은 Index 생성시 "settings"에 들어가는 부분입니다.
{ "number_of_shards" : "1", "number_of_replicas" : "1", "analysis": { "analyzer": { "seminar_name_analyzer": { "type": "custom", "char_filter": ["html_strip"], "tokenizer": ["nori_discard" ], "filter": ["lowercase", "english_stop_filter", "standard", "snowball" ,"nori_part_of_speech"] }, "seminar_explanation_analyzer": { "type": "custom", "char_filter": [], "tokenizer": ["nori_discard"], "filter": ["lowercase", "english_stop_filter", "snowball", "standard", "nori_part_of_speech"] } }, "tokenizer": { "nori_discard": { "type": "nori_tokenizer", "decompound_mode": "discard" } }, "filter": { "english_stop_filter": { "type": "stop", "stopwords": ["a", "an", "the", "is", "at", "on", "in", "of", "and", "or"] }, "korea_stop_filter": { "type": "stop", "stopwords": ["은", "는", "이", "가", "을", "를", "에", "와", "과", "나", "너", "그", "저"] "stoptags": ["E", "J"] } } } }
1-3-2. es-member-settings.json
아래의 설정은 Index 생성시 "mappings"에 들어가는 부분입니다.
{ "properties": { "seminar_no" : { "type" : "long" }, "seminar_name": { "type": "text", "analyzer": "seminar_name_analyzer", "fields" : { "keyword": { "type": "keyword", "ignore_above" : 256 } } }, "seminar_explanation" : { "type" : "text", "analyzer": "seminar_explanation_analyzer" }, "seminar_max_participants" : { "type" : "long" }, "inst_dt" : { "type" : "date" }, "updt_dt" : { "type" : "date" } } }
2. 검색기능을 만들어봅니다.
seminar_name과 seminar_explanation 에 따라서 검색할 수 있도록 구현합니다.
2-1. PageRequestDTO.java
검색 시 조건분기에 사용할 PageRequestDTO 입니다.
@Builder @AllArgsConstructor @Data public class PageRequestDTO { private int page; private int size; private String type; private String keyword; public PageRequestDTO(){ this.page = 1; this.size = 10; } public Pageable getPageable(Sort sort){ return PageRequest.of(page -1, size, sort); } }
2-1. SeminarElasticSearchServiceImpl.java [ Criteria를 활용할경우 ]
Criteria를 활용하여 검색합니다. 이때 깔끔한 코드 구성을 위해 CriteriaQuery를 createSearchCriteriaQuery에서 생성하도록 합니다.
@Override public SearchHits<SeminarDocument> searchByKeywordAndType(PageRequestDTO pageRequestDTO, Pageable pageable) { CriteriaQuery query = createSearchCriteriaQuery(pageRequestDTO,pageable); SearchHits<SeminarDocument> searchHits = elasticsearchOperations.search(query, SeminarDocument.class); return searchHits; } private CriteriaQuery createSearchCriteriaQuery(PageRequestDTO pageRequestDTO, Pageable pageable) { CriteriaQuery query = new CriteriaQuery(new Criteria()); if(!StringUtils.hasText(pageRequestDTO.getKeyword())){ return query; } String keyword = pageRequestDTO.getKeyword(); if(pageRequestDTO.getType().contains("seminar_name")){ query.addCriteria(Criteria.where("seminar_name").is(keyword)); } if(pageRequestDTO.getType().contains("seminar_explanation")){ query.addCriteria(Criteria.where("seminar_explanation").is(keyword)); } query.setPageable(pageable); return query; }
2-2 SeminarElasticSearchRepositoryTests.java
검색테스트를 진행합니다.
@DisplayName("elasticsearch search test") @Test public void testSeminarSearch(){ Long startTime = System.currentTimeMillis(); PageRequestDTO pageRequestDTO = PageRequestDTO.builder() // .keyword("엘라스틱 서치 검색 테스트에요") .keyword("eastwood") .type("seminar_explanation seminar_name") // .type("seminar_name") .page(0) .size(10) .build(); Pageable pageable = PageRequest.of(0, 10); SearchHits<SeminarDocument> searchHits = seminarElasticSearchService.searchByNativeQueryKeywordAndType(pageRequestDTO, pageable); Long endTime = System.currentTimeMillis(); System.out.println("Execution Time:"+ (endTime - startTime) + "ms"); System.out.println(searchHits.getTotalHits()); System.out.println(searchHits.getMaxScore()); for (SearchHit<SeminarDocument> searchHit : searchHits) { System.out.println(searchHit.getContent().toString()); } }
이와 같이 Criteria를 사용할경우 깔끔하게 코드를 작성할 수 있습니다만, Criteria의 경우 Match 쿼리가 발동하면서 Filter 쿼리로써의 처리가 불가합니다.
아래의 실행사항을 보면, MaxScore가 보이며 ElasticSearch 검색알고리즘에서 점수를 계산한 값을 볼 수 있습니다.
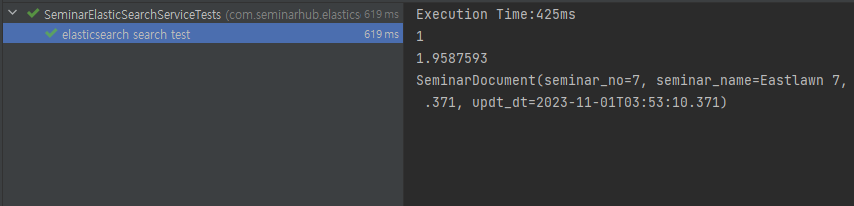
Score에 따라서 값을 반환해주는 Match 쿼리도 필요하지만, Score와 상관없이 해당하는 값을 Searching 할때 사용할 수 있는 NativeQuery를 활용하여 진행해보겠습니다.
2-3. SeminarElasticSearchServiceImpl.java [ NativeQuery 를 활용할경우 ]
Native Query를 활용하여 검색합니다. 비교적 깔끔한 코드 구성이 어렵습니다. 각 조건별로 함수를 만들어서 진행하여도 되지만, 직관적인 모습으로 코딩을 해보겠습니다.
@Override public SearchHits<SeminarDocument> searchByNativeQueryKeywordAndType(PageRequestDTO pageRequestDTO, Pageable pageable) { Query query = NativeQuery.builder() .withQuery(q -> q .bool(b -> b .filter(f -> { if (pageRequestDTO.getType().contains("seminar_name") && pageRequestDTO.getType().contains("seminar_explanation")) { // seminar_name과 seminar_explanation이 둘다 주어진경우 return f.bool(b1 -> b1 .should(mq -> mq .match(mq1 -> mq1 .field("seminar_name") .query(pageRequestDTO.getKeyword()))) .should(mq -> mq .match(mq1 -> mq1 .field("seminar_explanation") .query(pageRequestDTO.getKeyword())))); } else if(pageRequestDTO.getType().contains("seminar_name") && !pageRequestDTO.getType().contains("seminar_explanation")){ // seminar_name만 주어진 경우 return f.bool(b1 -> b1 .should(mq -> mq .match(mq1 -> mq1 .field("seminar_name") .query(pageRequestDTO.getKeyword())))); } else if(!pageRequestDTO.getType().contains("seminar_name") && pageRequestDTO.getType().contains("seminar_explanation")){ // seminar_explanation만 주어진 경우 return f.bool(b1 -> b1 .should(mq -> mq .match(mq1 -> mq1 .field("seminar_explanation") .query(pageRequestDTO.getKeyword())))); } return f.bool(b1 -> b1); } ) ) ) .withPageable(pageable) .build(); SearchHits<SeminarDocument> searchHits = elasticsearchOperations.search(query, SeminarDocument.class); return searchHits; }
2-4 SeminarElasticSearchRepositoryTests.java
검색테스트를 진행합니다.
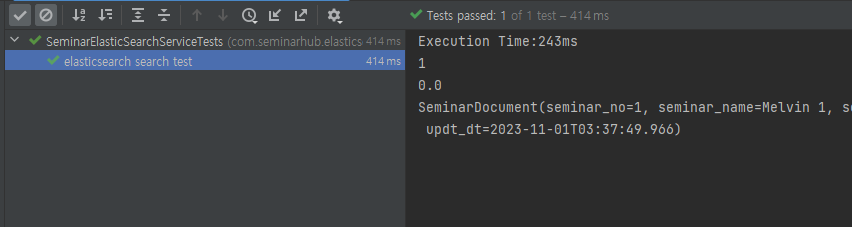
@DisplayName("elasticsearch search test") @Test public void testSeminarSearch(){ Long startTime = System.currentTimeMillis(); PageRequestDTO pageRequestDTO = PageRequestDTO.builder() // .keyword("엘라스틱 서치 검색 테스트에요") .keyword("eastwood") .type("seminar_explanation seminar_name") // .type("seminar_name") .page(0) .size(10) .build(); Pageable pageable = PageRequest.of(0, 10); SearchHits<SeminarDocument> searchHits = seminarElasticSearchService.searchByNativeQueryKeywordAndType(pageRequestDTO, pageable); Long endTime = System.currentTimeMillis(); System.out.println("Execution Time:"+ (endTime - startTime) + "ms"); System.out.println(searchHits.getTotalHits()); System.out.println(searchHits.getMaxScore()); for (SearchHit<SeminarDocument> searchHit : searchHits) { System.out.println(searchHit.getContent().toString()); } }
Native Query를 사용할경우 아래와 같이 최대 MaxScore가 0 이다. Filter가 올바르게 적용되었습니다.
마무리
이로써 ElasticSearch 에 Seminar의 데이터 분석 모델링을 진행해보고, Spring Data ElasticSearch의 API를 활용하여 개발을 완료했습니다.
이러한 ElasticSearch는 역인덱스 구조로 저장됨으로써 많은 데이터가 생기더라도 빠르게 검색할 수 있고, 이러한 성능차이는 데이터가 많아질수록 기존의 RDBMS와 성능차이가 눈에 띄게 커질 것 입니다.
Spring Data ElasticSearch와 관련된 정보는 아래의 글에서 확인할 수 있습니다.
https://docs.spring.io/spring-data/elasticsearch/docs/current/reference/html/
Spring Data Elasticsearch - Reference Documentation
The Spring Data infrastructure provides hooks for modifying an entity before and after certain methods are invoked. Those so called EntityCallback instances provide a convenient way to check and potentially modify an entity in a callback fashioned style. A
docs.spring.io