
https://kafka.apache.org/documentation/#gettingStarted
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
공식 레퍼런스를 참조하여 저의 개인적인 생각을 정리해봤습니다.
처음 정리하는거라 이번 글에서는 Documentation에서 Getting Started 부분만 정리할 것입니다.
1.카프카의 Event Streaming에 대하여

Event Streaming이란 인간의 중앙신경 시스템과 같은 것을 의미합니다.
즉, 인간의 중앙신경(뇌??)가 온몸의 정보들을 받아서 처리하는 것처럼
Kafka 또한 온 소프트웨어의 데이터를 Kafka가 받아 뇌의 역할을 한다고 이해하면 될것 같습니다.
스프링 입장에서 보면 Kafka라는 컨트롤러가 존재하여 모든 데이터가 오는 느낌일 것 같습니다.
Event Streaming이 사용될 수 있는 분야는 무엇이 있을까??
- 증권 거래소, 은행, 보험 등에서 실시간으로 결제 및 금융 거래를 처리하기 위해.
- 물류 및 자동차 산업과 같은 자동차, 트럭, 함대 및 선적을 실시간으로 추적하고 모니터링합니다.
- 공장 및 풍력 단지와 같은 IoT 장치 또는 기타 장비에서 센서 데이터를 지속적으로 캡처하고 분석합니다.
- 소매, 호텔 및 여행 산업, 모바일 애플리케이션과 같은 고객 상호 작용 및 주문을 수집하고 즉시 반응합니다.
- 병원 치료 중인 환자를 모니터링하고 상태 변화를 예측하여 응급 상황에서 적시에 치료할 수 있도록 합니다.
- 회사의 여러 부서에서 생성된 데이터를 연결, 저장 및 사용 가능하게 만드는 것.
- 데이터 플랫폼, 이벤트 기반 아키텍처 및 마이크로서비스의 기반 역할을 합니다.
이렇게 예시를 쭉봐보면 일반적으로 컴퓨팅 작업이 부화될 수 있는 작업이며
여러 작업들이 함께 일어나는 작업들입니다.
일반적으로 소프트웨어가 사용되는 방식이되, 좀 더 Event가 발생하며 그 과정에서 발생하는 여러 일들을 안정적으로 처리하도록 도와준다고 생각하면 될 것 같습니다.
Apache Kafka는 Event Streaming Platform이다. 그것이 무엇을 의미하는가??
Kafka는 세가지 주요 기능을 활용하여 이벤트 스트리밍에 대한 사례에 대해 적용할 수 있습니다.
- To publish (write) and subscribe to (read) streams of events, including continuous import/export of your data from other systems.
- To store streams of events durably and reliably for as long as you want.
- To process streams of events as they occur or retrospectively.
1. 다른 시스템에서 오는 데이터들을 pub/sub 할 수 있고.
2. 그 데이터들을 안정감있고 신뢰성있게 저장하고
3. 그 일련의 이벤트들을 처리하게 할 수 있다.
이렇게 해석하면 될것같습니다.
뭔가 Event Streaming이라고 해서 상당히 복잡해보이는데 (낯선단어네요)
일반적으로 사용되는 Pub/sub 역할을 한다고 보면 되겠네요.
Kafka는 간단히 말해서 어떻게 작동합니까?
kafka는 server와 클라이언트로 이루어진 분산형 시스템으로써 TCP network protocol을 활용한 높은 활용성을 가지고 있습니다.
Server 측면 : Kafka는 여러 데이터 센터 또는 클라우드 지역에 걸쳐 있을 수 있는 하나 이상의 서버 클러스터로 실행됩니다. 이러한 서버 중 일부는 브로커라고 하는 스토리지 계층을 형성합니다. 다른 서버는 Kafka Connect를 실행하여 데이터를 이벤트 스트림으로 지속적으로 가져오고 내보내어 Kafka를 관계형 데이터베이스 및 기타 Kafka 클러스터와 같은 기존 시스템과 통합합니다. 미션 크리티컬 사용 사례를 구현할 수 있도록 Kafka 클러스터는 확장성이 뛰어나고 내결함성이 있습니다. 서버 중 하나에 오류가 발생하면 다른 서버가 작업을 인계받아 데이터 손실 없이 지속적인 운영을 보장합니다.
--> 간단정리: 서버가 여러개일때도 데이터를 공유하며 Kafka가 작동한다는 의미입니다.
이것이 정말 큰 장점인 것 같습니다.
이 기능을 통해 서버가 고장나도 한개는 작동을 할 수 있게 할 수 있습니다.
Clients 측면 : 이를 통해 네트워크 문제나 시스템 오류가 발생한 경우에도 대규모로 내결함성 방식으로 이벤트 스트림을 병렬로 읽고 쓰고 처리하는 분산 애플리케이션 및 마이크로 서비스를 작성할 수 있습니다. Kafka는 Kafka 커뮤니티에서 제공하는 수십 개의 클라이언트로 보강된 일부 클라이언트와 함께 제공됩니다. 클라이언트는 Go, Python, C/C++ 및 기타 여러 프로그래밍을 위한 상위 수준 Kafka Streams 라이브러리를 포함하여 Java 및 Scala에서 사용할 수 있습니다. 언어뿐만 아니라 REST API.
--> 간단정리 : 클라이언트는 여러 언어에서도 Kafka를 사용할 수 있다는 의미입니다.
주요 개념 및 용어
Event는 "어떤 일이 발생" 하면 이것을 기록합니다. 이것은 또한 record 혹은 메세지 라고도 Reference에서는 말합니다.
개발자가 Kafka에 data를 읽거나 쓸때, 이것을 Event의 형식으로 작성합니다.
개념적으로, 이벤트는 key, value, timestamp, 그리고 선택적인 metadata headers. 가 있습니다.
예시가 있습니다.
- Event key: "Alice"
- Event value: "Made a payment of $200 to Bob"
- Event timestamp: "Jun. 25, 2020 at 2:06 p.m."
--> 간단정리 : Event라는 class가 있다고 가정하고 그 안에 key, value, timestamp 가 있다고 생각하면 됩니다.
이것을 Event VO 객체로 만들어서 데이터를 왔다갔다 저장하게 하는 것 같습니다.
Producers 는 Publisher 역할. client applications으로써 Kafka에 데이터를 Publish, Write 작성합니다.
Consumers 는 Subscriber 역할. Publisher가 Publish한 Event들을 Subscribe, Read 합니다.
Kafka에서는 Kafka에서 Producer와 Consumer는 완전히 분리되어 서로 불가지론적입니다.
Kafka의 높은 확장성을 구현하기 위한 핵심 설계 요소입니다.
예를 들어 생산자는 소비자를 기다릴 필요가 없습니다. Kafka는 이벤트를 정확히 한 번 처리하는 기능과 같은 다양한 보장을 제공합니다.
--> Kafka에서 Producer와 Consumer는 완전히 분리되어 있다는 것이 높은 확장성을 구현하도록 하는 것 같습니다.
만약, 서로 얽키고 얽혀 있다면 복잡한 프로그램에서 높은 확장성을 가지기 쉽지 않겠지요.
이벤트는 주제에 구성되고 영구적으로 저장됩니다.
매우 단순화된 topic은 파일 시스템의 폴더와 유사하며 이벤트는 해당 폴더의 파일입니다.
예시 topic은 "payments"(결제) 가 될 수 있습니다.
--> Kafka에서 재미있는 예시를 주었는데
"결제"라는 폴더가 존재한다면, 이벤트로는 "어떤 사람이 결제한 데이터"를 의미할 수 있을 것 같습니다.
Kafka의 토픽은 항상 다중 생산자이자 다중 구독자입니다. 토픽에는 이벤트를 쓰는 0개, 1개 또는 많은 생산자와 이러한 이벤트를 구독하는 0개, 1개 또는 많은 소비자가 있을 수 있습니다.
토픽의 이벤트는 필요한 만큼 자주 읽을 수 있습니다. 기존 메시징 시스템과 달리 이벤트는 소비 후 삭제되지 않습니다.
대신 Kafka가 주제별 구성 설정을 통해 이벤트를 유지해야 하는 기간을 정의합니다. 그 후에는 이전 이벤트가 삭제됩니다.
Kafka의 성능은 데이터 크기와 관련하여 실질적으로 일정하므로 장기간 데이터를 저장해도 괜찮습니다.
--> 이벤트가 소비 후 삭제되지 않는다는 것?? 어떤식으로 소비 후 삭제되지 않는지 궁금.
--> Data의 크기와 관련하여 데이터가 일정하다는 점
주제는 분할됩니다. 즉, 주제가 다른 Kafka 브로커에 있는 여러 "버킷"에 분산되어 있습니다.
데이터의 이러한 분산 배치는 클라이언트 애플리케이션이 여러 브로커에서 동시에 데이터를 읽고 쓸 수 있도록 하기 때문에 확장성에 매우 중요합니다.
새 이벤트가 주제에 게시되면 실제로 주제의 파티션 중 하나에 추가됩니다.
동일한 이벤트 키(예: 고객 또는 차량 ID)가 있는 이벤트는 동일한 파티션에 기록되며 Kafka는 지정된 주제 파티션의 소비자가 항상 해당 파티션의 이벤트를 작성된 순서와 정확히 동일한 순서로 읽도록 보장합니다.
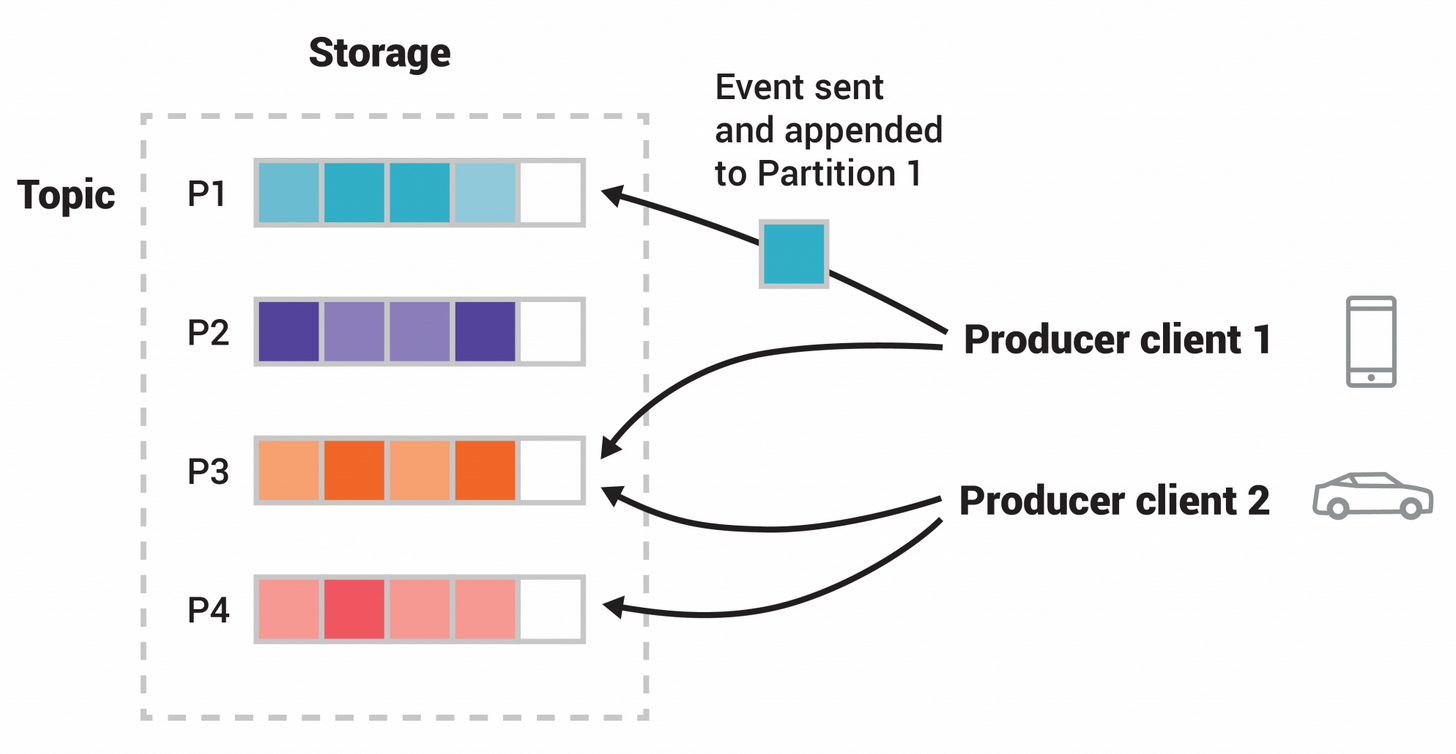
위 왼쪽 Storage 부분을 보면 Topic이 4개의 Partition 으로 나뉘어져 있습니다. P1, P2, P3, P4. 가 있네요.
그리고 오른쪽을 보면 Producer client 1(핸드폰 모양), Producer client 2(자동차 모양)이 각각의 Topic Partition에 네트워크를 통해 독립적으로 Topic에 이벤트를 추가하고 있습니다.
Producer client1은 P1과 P3 topic에
Producer client2은 P3와 P4 topic에 이벤트를 추가하고 있는 모양입니다.
Key가 같은 이벤트(그림에서 색상으로 표시됨)는 동일한 파티션에 기록됩니다.
아까 위에서
- Event key: "Alice"
- Event value: "Made a payment of $200 to Bob"
- Event timestamp: "Jun. 25, 2020 at 2:06 p.m."
이 Event 객체의 Key가 어느 topic으로 갈지 결정합니다.
데이터 내결함성 및 고가용성을 만들기 위해 모든 주제는 지역 또는 데이터 센터 간에도 복제될 수 있으므로 일이 잘못될 경우를 대비하여 항상 데이터 사본을 가지고 있는 여러 브로커가 있습니다.
브로커에 대한 유지 관리 등을 수행합니다.
일반적인 프로덕션 설정은 복제 계수 3입니다. 즉, 항상 데이터 복사본이 3개 있습니다.
이 복제는 주제 파티션 수준에서 수행됩니다.
--> Kafka는 항상 일이 잘못될 것을 대비하여 3개의 데이터 복사본을 준비하고 있다고 합니다.
이정도까지가 사용자를 위한 입문서이고, 정말 더 자세하게 알고싶다면 https://kafka.apache.org/documentation/#design
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
로 들어가서 확인하시면 됩니다.
'기타 > kafka' 카테고리의 다른 글
| [Spring] Kafka [2](카프카 Quick Tour with Java Configuration) (0) | 2023.01.26 |
|---|