
https://docs.spring.io/spring-kafka/reference/html/#quick-tour
Spring for Apache Kafka
When using Spring for Apache Kafka in a Spring Boot application, the Apache Kafka dependency versions are determined by Spring Boot’s dependency management. If you wish to use a different version of kafka-clients or kafka-streams, and use the embedded ka
docs.spring.io
Sprng에서 제공하는 Apache Kafka quic tour documentation을 읽어보면서 해석과 함께 한번 카프카 실습을 진행해보겠습니다.
저 같은경우 Spring을 사용할때 Java Configuration으로 하는 것을 좋아하므로
Spring Quick Tour에서 제공하는 With Java Configuration ( No Spring Boot ) 로 진행하겠습니다.
Spring for Apache Kafka 는 Spring Application Context 에서 사용되도록 디자인되었습니다.
예시로 들어보면, 만약 당신이 Listener container를 Spring Context 외부에 생성한다면
모든 기능들이 당신이 container에서 제공되는 interface를 구현하기 전까지 작동하지 않습니다.
--> 스프링 Bean 설정을 위한 @Configuration, @Bean 을 잘관리하라는 의미입니다.
Spring의 콘텍스트에 저장을 하여 필요한 객체에게 주입하기 위한 @Bean 등록 지키라는 의미/.
[전제조건]. 먼저 Apache Kafka와 Zookeeper 설치하고 작동하고 있는 상황이어야합니다.
저같은 경우 AWS EC2에 Kafka와 Zookeeper를 설치해두었습니다.
[step 1].Kafka를 Maven을 통해 Build합니다.
Quick Tour에서는 Spring-kafka 3.0.2를 사용하고 있는데
Spring-kafka 3.0.2를 사용할경우 -Minimum Java Version : 17 이기에
저는 Java 1.8을 사용하고 있는 환경이므로 Spring-kafka 1.0.0 을 사용하여 진행하겠습니다.
<!-- https://mvnrepository.com/artifact/org.springframework.kafka/spring-kafka --> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> <version>1.0.0.RELEASE</version> </dependency>
[step 2]. Configuration 파일을 생성합니다.
저는 [org.kafka.example.KafkaConfig.java] 에 생성했습니다.
Kafka를 사용하기 위한 설정파일입니다.
@Configuration @EnableKafka public class KafkaConfig { //KafkaListenerContainerFactory는 kafkalistenercontainer를 사용하도록 설정합니다. //이 함수를 통해 Consumer에서 사용할 @KafkaListner 어노테이션이 제대로 작동합니다. (Consumer Code에 나옵니다.) //추가설명은 https://docs.spring.io/spring-kafka/docs/1.1.1.RELEASE/api/org/springframework/kafka/annotation/KafkaListener.html @Bean ConcurrentKafkaListenerContainerFactory<Integer, String> kafkaListenerContainerFactory(ConsumerFactory<Integer, String> consumerFactory) { ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory); return factory; } //ConsumerProps()에서 생성된 Consumer 설정파일을 토대로 DefaultKafkaConsumerFactory()를 생성하여 리턴합니다. //DefaultKafkaConsumerFactory()란 Kafka Consumer가 작동하기 위한 설정파일입니다. @Bean public ConsumerFactory<Integer, String> consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerProps()); } private Map<String, Object> consumerProps() { Map<String, Object> props = new HashMap<>(); //: 어떤 서버와 연동할지 알려줍니다. 9092는 카프카의 전용 포트입니다. props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); //GroupIP를 설정합니다.. props.put(ConsumerConfig.GROUP_ID_CONFIG, "group"); //역직렬화를 진행합니다. 반대로 Producer에서는 직렬화를 진행하겠지요? props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); //offset이란 메세지를 어디까지 읽었느냐를 체크해주는 변수입니다. //"earliest"라는 인자는 Consumer입장에서 가장 오래된 offset부터 consuming 합니다. props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); // ... return props; } //Listener Class 사용을 위해 @Bean으로 등록합니다. @Bean public Listener listener() { return new Listener(); } //Sender Class 사용을 위해 @Bean으로 등록합니다. @Bean public Sender sender(KafkaTemplate<Integer, String> template) { return new Sender(template); } //senderProps()에서 생성된 Sender 설정파일을 토대로 DefaultKafkaProducerFactory()를 생성하여 리턴합니다. //DefaultKafkaProducerFactory()란 Kafka Producer가 KafkaContainer에서 작동하기 위한 설정파일입니다. @Bean public ProducerFactory<Integer, String> producerFactory() { return new DefaultKafkaProducerFactory<>(senderProps()); } private Map<String, Object> senderProps() { Map<String, Object> props = new HashMap<>(); //: 어떤 서버와 연동할지 알려줍니다. 9092는 카프카의 전용 포트입니다. props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); //메세지를 보내기 전에 추가적인 메세지들을 위해 기다리는 시간을 설정합니다. //batch size가 꽉 찰 수 있도록 시간을 설정하면 전송횟수가 줄어듭니다. props.put(ProducerConfig.LINGER_MS_CONFIG, 10); //직렬화를 진행합니다. 반대로 Consumer에서는 직렬화를 진행하겠지요? props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); //... return props; } //kafka template은 kafka producer() 인스턴스를 감싸고 있다고 생각합니다. @Bean public KafkaTemplate<Integer, String> kafkaTemplate(ProducerFactory<Integer, String> producerFactory) { return new KafkaTemplate<Integer, String>(producerFactory); } }
[step 3] [org.kafka.example.Sender.java] 를 생성합니다. Producer 역할입니다.
public class Sender { //AnnotationConfigApplicationContext을 통해 자바설정에서 정보를 읽어와 //Bean 객체를 생성하고 관리합니다. //스프링 ApplicationContext에 정의한 @Bean 객체를 가져온다고 생각하면 됩니다. public static void main(String[] args) { AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(Config.class); //"test"라는 내용을 보내고, 0은 파티션의 위치입니다. 저는 topic 생성시 partition을 따로 설정안했기에 //0으로 설정했습니다. context.getBean(Sender.class).send("test", 0); } //KafkaProducer를 감싸고 있는 KafkaTemplate입니다. private final KafkaTemplate<Integer, String> template; //Sender 객체를 생성합니다. public Sender(KafkaTemplate<Integer, String> template) { this.template = template; } //"topic1": 말그대로 어느 topic에 보낼지 설정합니다. key : 파티션 toSend : 내용 public void send(String toSend, int key) { this.template.send("topic1", key, toSend); } }
[step 4] [org.kafka.example.Listener.java] 를 생성합니다. Consumer 역할입니다.
public class Listener { //topic1에 메세지가 들어올때 @KafkaListener 어노테이션이 작동하여 //해당 메세지를 바로 화면에 띄어줍니다. @KafkaListener(id = "listen1", topics = "topic1") public void listen1(String in) { System.out.println(in); } }
이렇게 하면 Quick Tour가 마무리됩니다.
[step 5] 실행
Sender.java에서 실행할시 topic1이 자동으로 생성되고 내용이 들어가고, Listener가 작동되면서 topic1에 데이터가 들어올시에 바로바로 console에 값을 출력해줍니다.
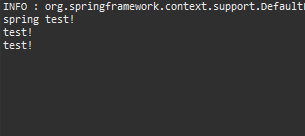
스프링 콘솔창에 이렇게 test! 가 들어가고 listener를 통해 다시 출력됩니다.
또한 실시간으로 AWS Kafka에서 topic1에 데이터를 넣을경우
bin/kafka-console-producer.sh --topic topic1 --bootstrap-server localhost:9092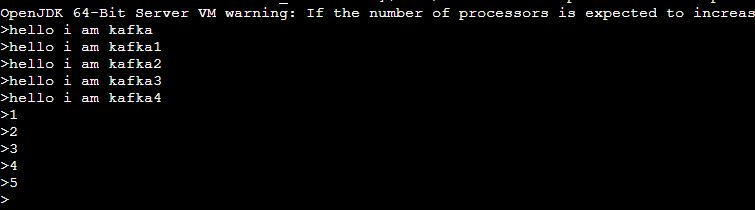
Spring Console창에 @KafkaListener가 작동하면서
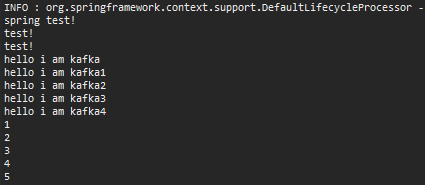
가 실시간으로 콘솔에 입력됩니다.
또 Spring Sender에서 넣은 값들을 확인하기 위해
bin/kafka-console-consumer.sh --topic topic1 --from-beginning --bootstrap-server localhost:9092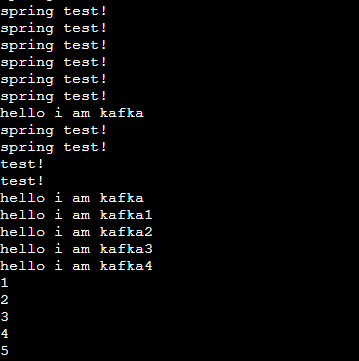
보면 아까 Sender에서 입력한 test!가 잘 들어간것을 확인할 수 있습니다.
'기타 > kafka' 카테고리의 다른 글
| [Spring] Kafka [1] (카프카 Getting Started) (0) | 2023.01.25 |
|---|